记录K8S pod频繁重启排查思路
起因
线上k8s集群某个服务的pod,频繁重启,导致线上接口频繁503
分析
先查看了pod重启的原因
kubectl describe pod -n xl-prod dxe-data-5789d76897-7p8zk
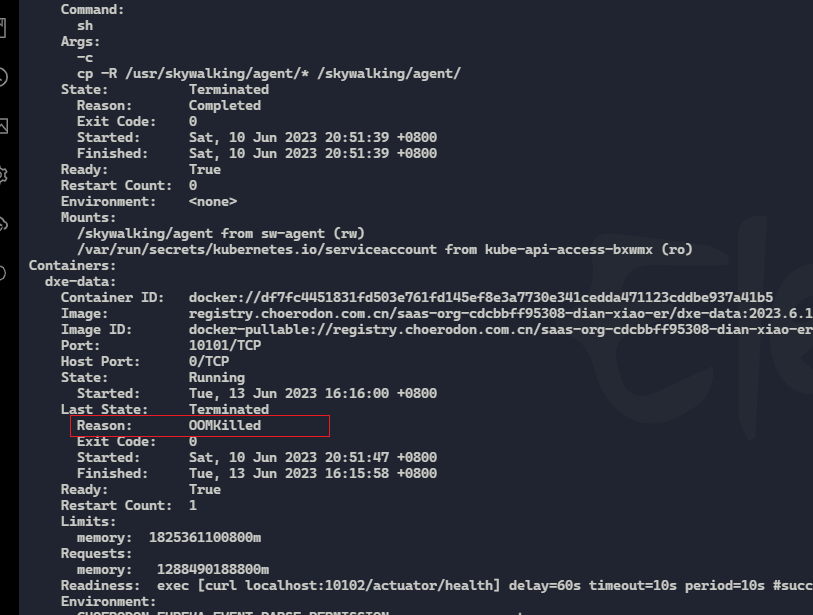
显示是oom内存溢出被杀掉了。
因为没有记录dump文件,暂时不好分析oom的原因
大致知道是内存的原因,进一步分析
进入pod容器,top查看进程占用
kubectl exec -it -n xl-prod dxe-data-5789d76897-7p8zk -- /bin/bash
top
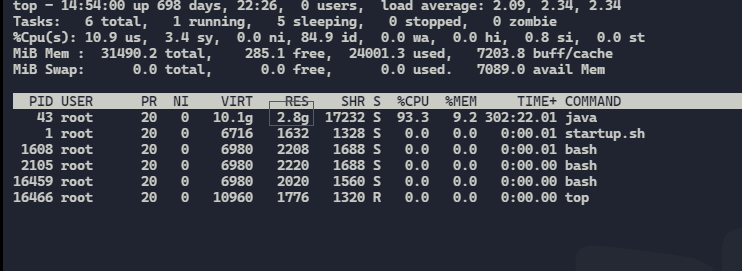
看到java进程实际占用内存2.8G
我的应用设置的JVM 最小堆内存为 2GB; JVM 最大堆内存为 4GB;JVM 新生代内存为 1GB

但是为什么进程只用到了2.8G pod就被oom杀掉了
后来发现我在设置pod资源限制的时候,设置了pod最大使用内存为4G
limits: memory: 4Gi 代表允许pod最大使用内存4G
requests: memory: 2Gi 代表pod启动立即分配2G内存
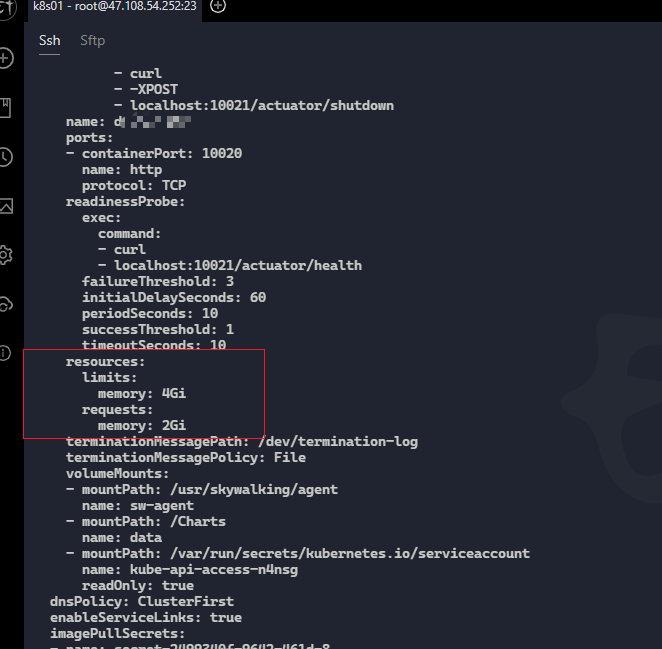
到这个时候思路就比较明显了
因为jvm设置了最大堆内存为4G,pod最大的内存也为4G,
但是pod里面除了java应用还有其他的一些进程会占用部分内存,jvm还有堆外内存和栈内存等,
所以pod给的4g内存留给java应用排除调堆外内存和栈内存和其他的一些进程占用的内存,而剩下的内存是小于java应用进程实际占用内存2.8G的 所以就会导致oom导致pod频繁重启
解决
由于这个应用业务比较复杂内存占用较高临时解决方案是
先把pod限制调高
limits: memory: 5Gi
requests: memory: 4Gi
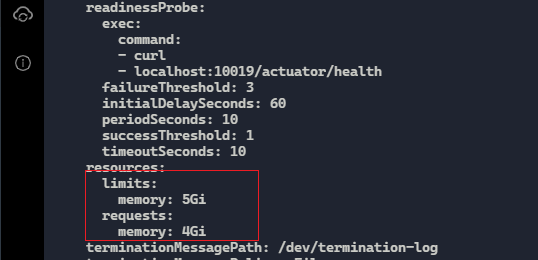
调整之后观察pod没有在频繁重启了

- 算记录一下生产事故的排查思路
合理的jvm设置参考
合理的 JVM 内存参数设置需要根据应用程序的实际情况来进行调整,以确保 JVM 在运行过程中有足够的内存和资源可用。以下是一些通用的建议:
设置最小堆内存 -Xms 和最大堆内存 -Xmx 为相同的值,以避免在 JVM 扩展内存时产生额外的开销。
根据物理机器的内存容量,分配相应的 JVM 内存大小。通常情况下,JVM 的堆内存可以设置为物理内存的 1/4 或 1/2。
如果应用程序需要处理大量数据或者执行复杂的计算操作,可以适当增加 JVM 堆内存的大小,以提高应用程序的性能。
如果应用程序需要频繁进行垃圾回收,可以适当增加 JVM 新生代内存的大小 -Xmn,以减少垃圾回收的次数和时间。
对于大型的 JVM 应用程序,建议将元空间初始大小 -XX:MetaspaceSize 和最大大小 -XX:MaxMetaspaceSize 分别设置为 256MB 和 512MB。
对于生产环境中的应用程序,建议开启服务器模式 -server,以提高 JVM 在处理大量请求时的效率。
综上所述,一个可能合理的设置如下:
-server -Xms4g -Xmx4g -Xmn1g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -XX:-OmitStackTraceInFastThrow
但需要注意的是,这只是一个通用的建议,具体的 JVM 内存参数设置应该根据应用程序的实际情况进行调整。